

July 7, 2011
With this last release in our series of dose-response improvements, we are very excited to introduce the following additions to your dose-response toolkit.
Dose-Response Plots Enhancement Galore
See All Your Plots
First, we have enhanced the way we generate dose-response plots so that the application always displays and exports plots even when the associated compound has been assayed many many many times. Yes, you know who you are.
Interactive Dose-Response Plots
Inspecting plots and flagging outliers on the 320x200 pixel plot used to be an exercise in patience and laser pointing accuracy. With this release, it is now possible to open any dose-response plot in a resizable interactive window.
Click on a plot or on the Arrow icon and a new Dose-response window opens up. This window can be expanded full screen and the plot resizes accordingly. From there, you can zoom in on any area of interest. Click on the Tips link to learn how to interact with the plot.
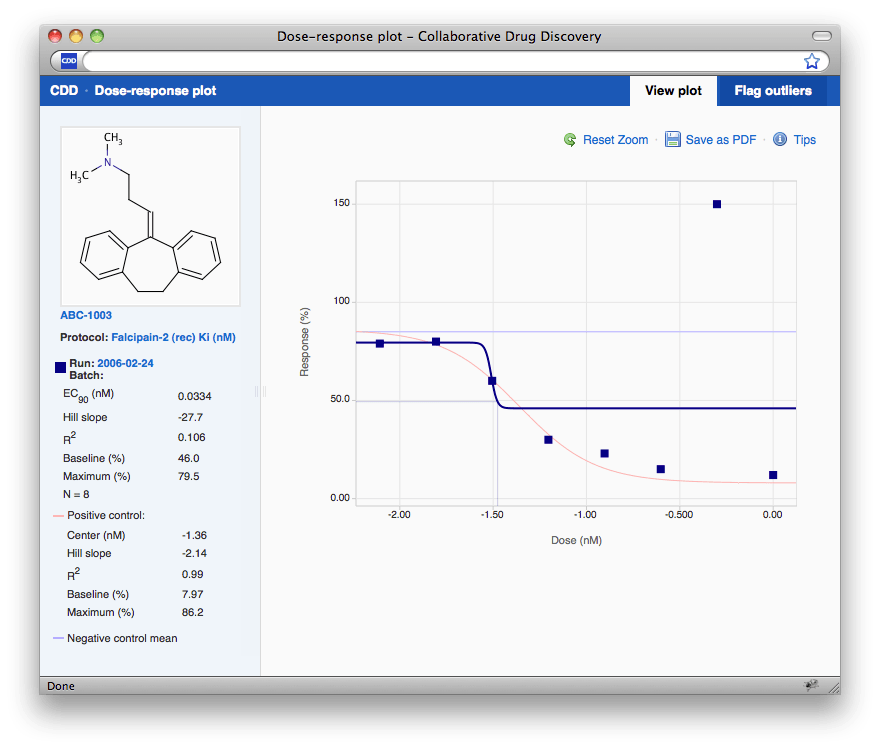
Notice the point that is clearly an outlier? Click on the “ Flag outliers & Override ” tab in the upper right-hand corner, and the Dose-response window switches to edit mode. Click on the point to flag it and you're done.
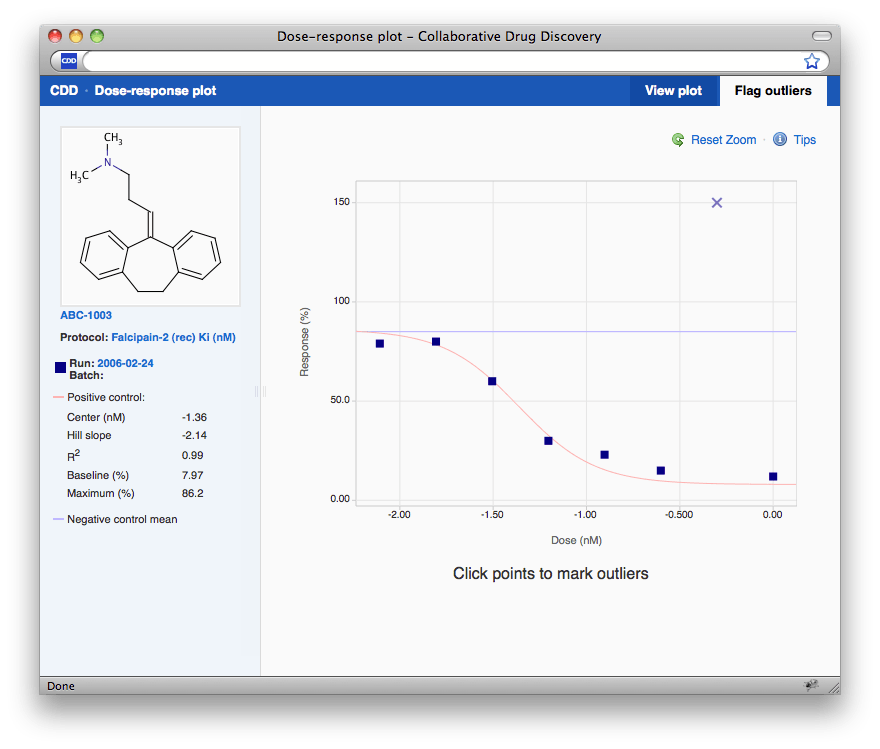
Once you switch back to see the plot or close the window, the data and plot in the search results will refresh automatically.
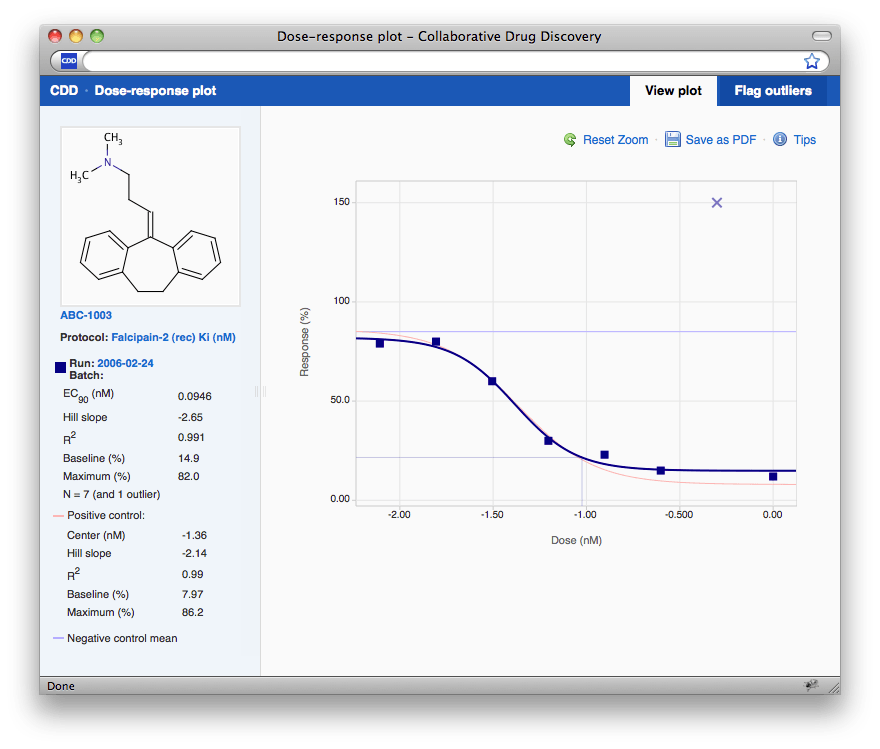
PDF Export
Like scatterplots, there is a link in the upper right-hand corner of the window to save the plot as a PDF. The PDF can then be dragged and dropped into PowerPoint or Microsoft Word for presentations and reports.
Consistent Color Coding
If you are visualizing dose-response data on the search results page, the points and curves for a specific run are now always drawn using the same color across all plots. The same color is also used in the pop-up window.
Sample Standard Deviation Out. Standard Error of The Mean In.
Error bars for data sets with replicates are now based on the standard error of the mean in place of the sample standard deviation. For in vitro systems with minimal biological variability, the standard error of the mean is more meaningful as it quantifies how accurately you know the true mean.
Dose-Response Curve Classification
In order to speedup the analysis of dose-response data, we have added support for curve classification as first proposed in "Quantitative high-throughput screening: A titration-based approach that efficiently identifies biological activities in large chemical libraries" by Inglese et al. Following the recommendations of Ajit Jadhav (one of the authors), we use an updated version of the classification found in the associated CurveFit program by Yuhong Wang, Ajit Jadhav and Noel Southall.
Curves are classified based on the quality of curve fit to the data (R2), the magnitude of the response (maximum activity), and the number of asymptotes.
| Curve class | Description | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Complete curve, showing multiple points near both asymptotes.
|
|||||||||||||||
| 2 | Partial curve, showing multiple points near only one asymptote. The subclasses 2.1, 2.2, 2.3 and 2.4 follow the same divisions as class 1 curves. |
|||||||||||||||
| 3 | Only one concentration shows significant activity. | |||||||||||||||
| 4 | Inactive. None of the tested concentrations show significant activity. |
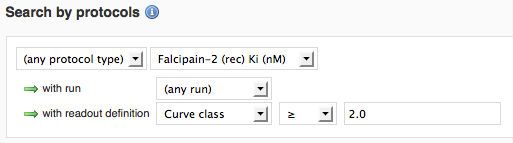
Curve classification requires positive and negative controls, so create a control layout on the Protocol Details page. Once this is done, you can search by curve class.
Improved Curve Fitting
In a few cases we were previously unable to fit a good curve because the Levenberg–Marquardt algorithm only finds a local minimum, and may miss the global minimum if it starts too far away from it. We now do a better job of picking the 'starting point' used for curve fitting, which has resolved all the problematic cases you've reported (thanks!).
These are all complex enhancements and we might have missed something, so if you notice any issues with your data or have feedback, please contact support.